@InProceedings{Han_2023_ICCV,
author = {Han, Sookwan and Joo, Hanbyul},
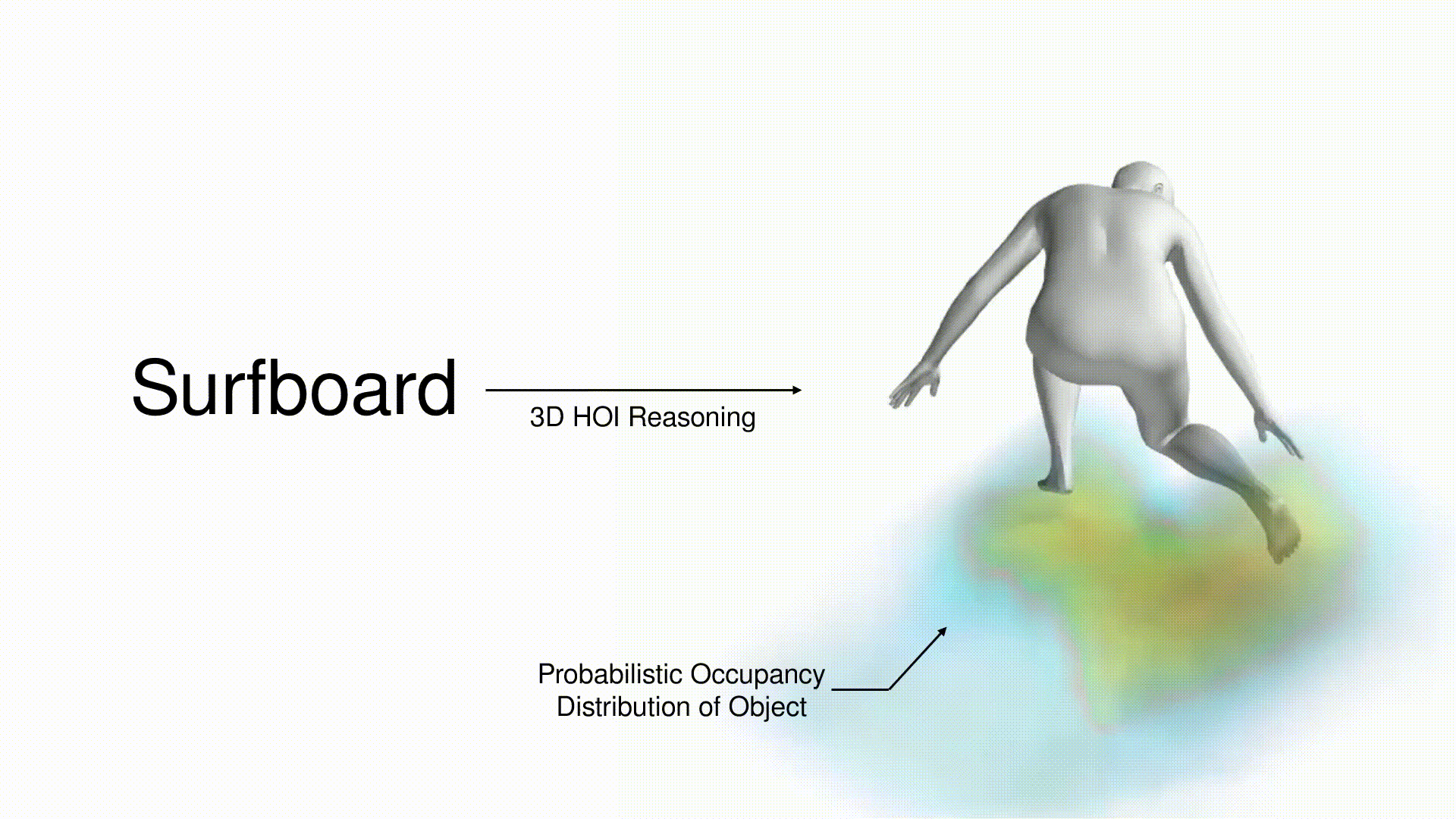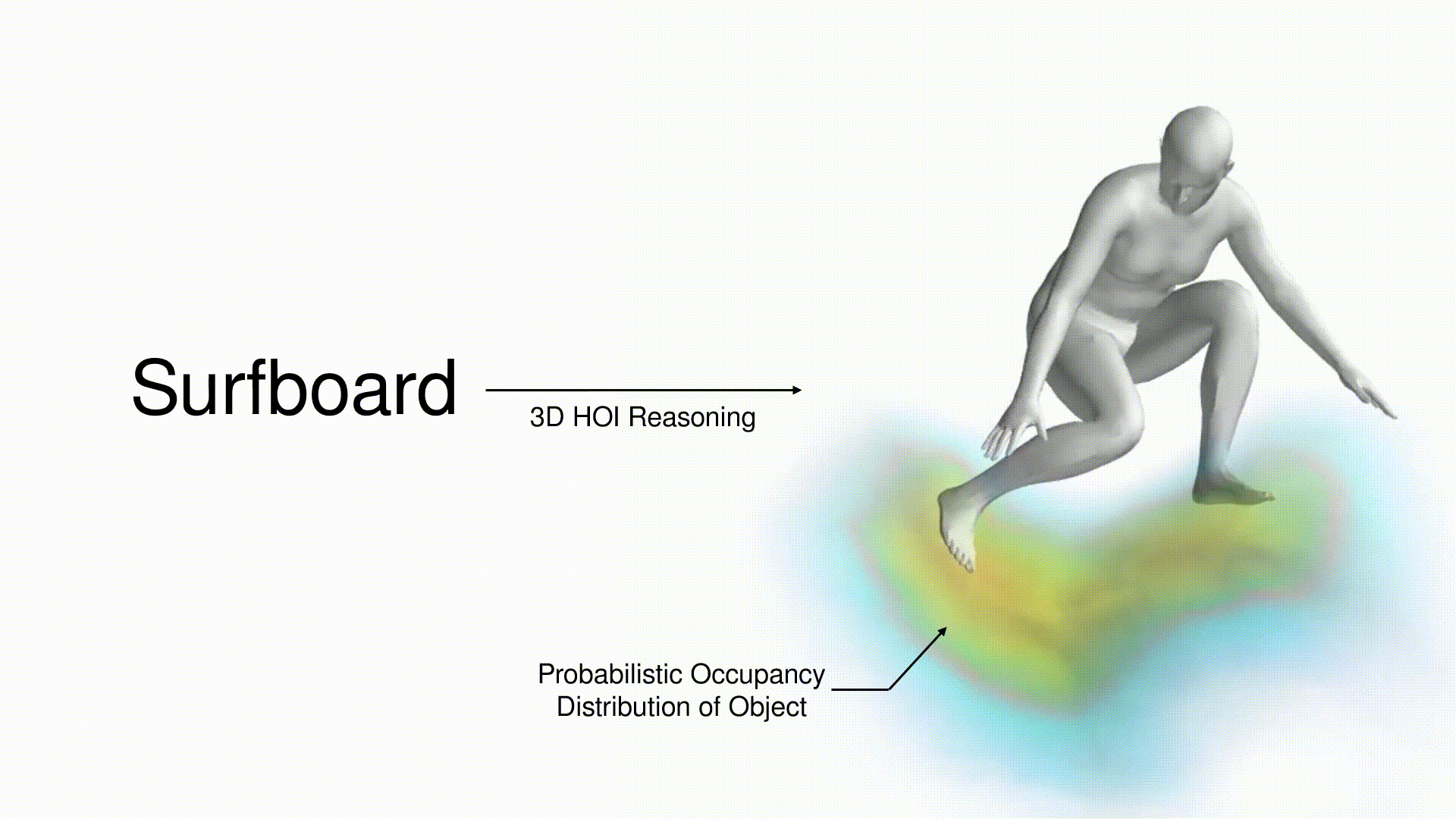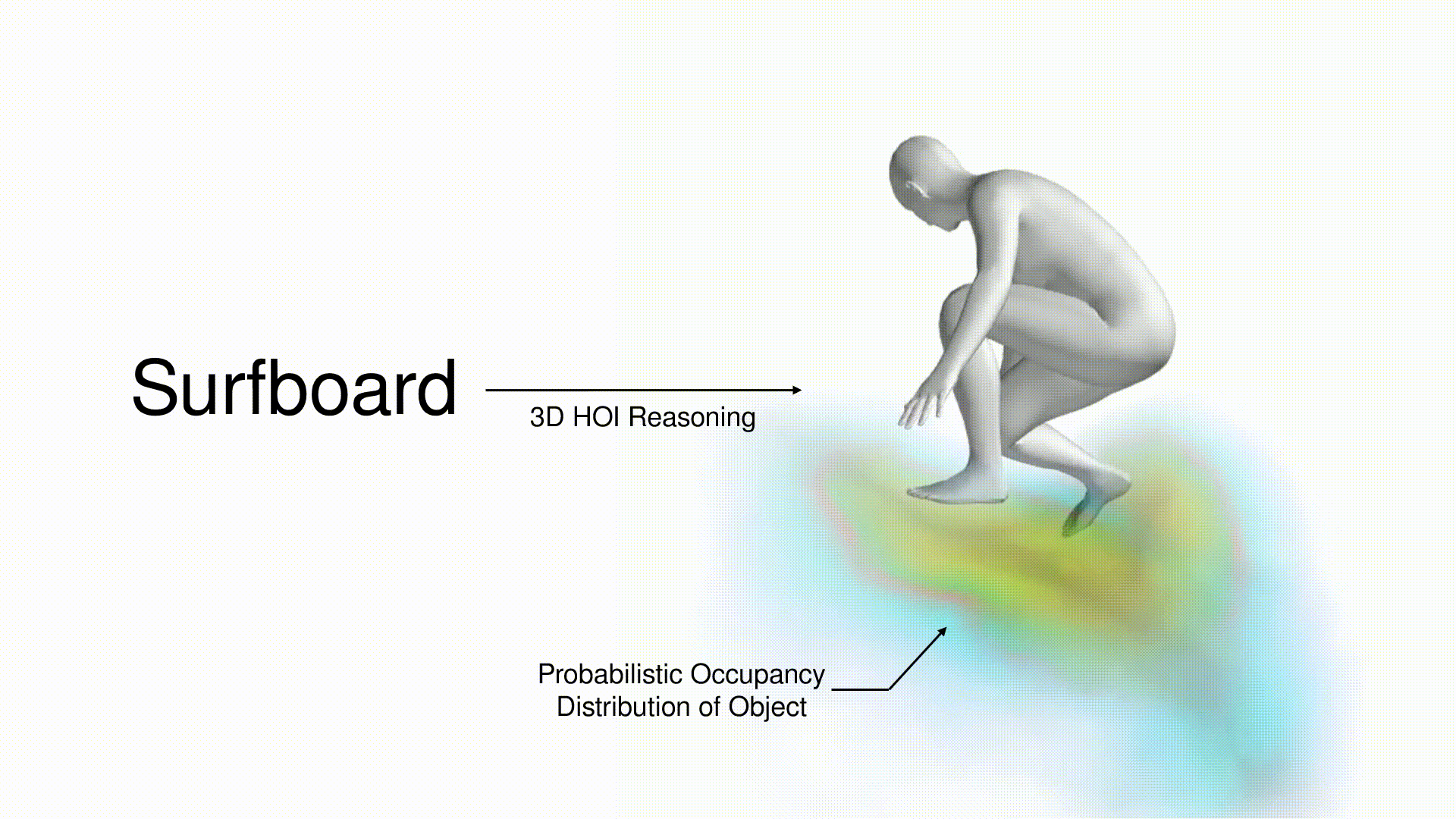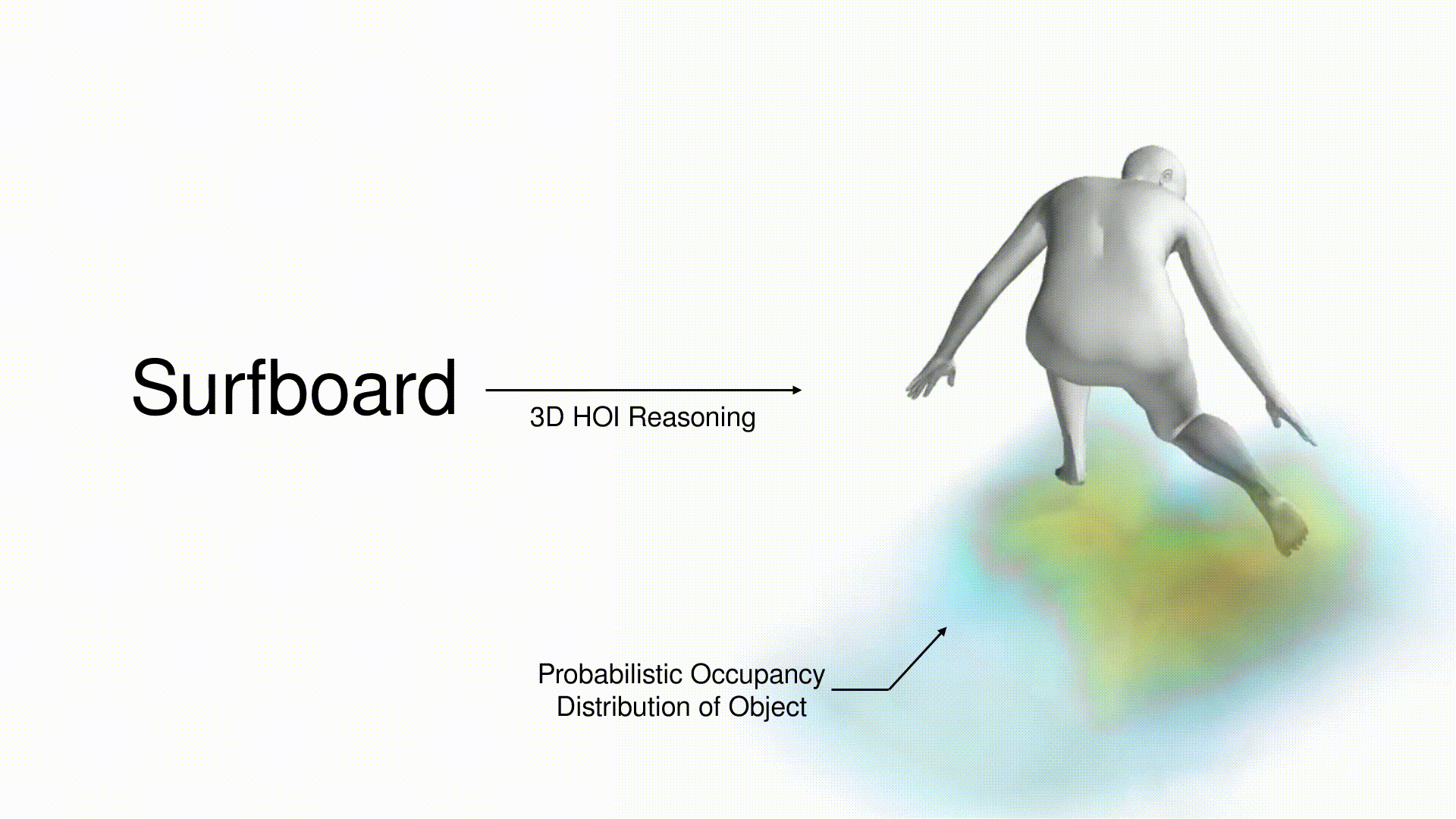
title = {CHORUS : Learning Canonicalized 3D Human-Object Spatial Relations from Unbounded Synthesized Images},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {15835-15846}
}